
The most popular workflow for git is still git-flow. I did a poll on Twitch with a friend some time ago and still over 50% of the audience said they were using it. And this is strange, because even Vincent Driessen, the author of the original post about git-flow, wrote a note in March 2020 in the post that git-flow is not the best workflow for cloud services, apps, or web applications. So why is it still so popular? I think there are three reasons:
- It’s very detailed, specific, and it provides guidance for people that are new to git.
- It has a great name that is good to memorize.
- It has a good visualization
And what’s the problem with GitHub Flow? Well, the name sounds too close to GitFlow and the description of the workflow is not very precise. How do you deploy? How do you work with long-lived feature branches? How do you support different versions for different customers?
I thinks what we need is a good new workflow with a good name and a nice chart! So let me introduce you to…
MyFlow
MyFlow is a lightweight, trunk-based workflow based on pull-requests. MyFlow is not a new invention! Many teams already work this way. It is a very natural way to branch and merge if you focus on collaboration with pull-request. I just try to give it a name and add some explanations for engineers that are new to git. So lets start…

The main branch
MyFlow is trunk-based – that means there is only one main branch called main. The main branch should always be in a clean state in which a new release can be created at any time. That’s why you should protect your main branch with a branch protection rule. A good branch protection rule would include:
- Require a minimum of two pull request reviews before merging.
- Dismiss stale pull request approvals when new commits are pushed.
- Require reviews from Code Owners.
- Require status checks to pass before merging that includes your CI build, test execution, code analysis, and linters.
- Include administrators in the restrictions.
- Permit force pushes.
The more you automate using the the workflow that is triggered by your pull request, the more likely it is that you can keep your branch in a clean state.
All other branches are always branched of main. Since this is your default branch, you never have to specify a source branch when you create new branches. This simplifies things and removes a source of error.
Private topic branches
Private topic branches can be used to work on new features, documentation, bugs, infrastructure, and everything else that is in your repository. They are private – so they belong to one specific user. Other team members can check out the branch to test it – but they are not allowed to directly push changes to this branch. Instead they must use suggestions in pull requests to suggest changes to the author of the pull request.
To indicate that the branches are private, I recommend a naming convention like users/* or private/* that makes this obvious. Don’t use naming conventions like features/* – they imply that multiple developers may work on one feature. I also recommend including the id of the issue or bug in the name. This makes it easy to reference it later in the commit message. A good convention would be:
users/<username>/<id>_<topic>
Private topic branches are low-complexity branches. If you work on a more complex feature, you should at least merge your changes back to main and delete the topic branch once a day using feature flags (aka feature toggles). If the changes are simple and can be easily rebased onto main, you can leave the branch open for a longer time. The branches are low-complexity and not short-lived.
So, to start working on a new topic you create a new branch locally:
$ git switch -c <branch-name>
For example:
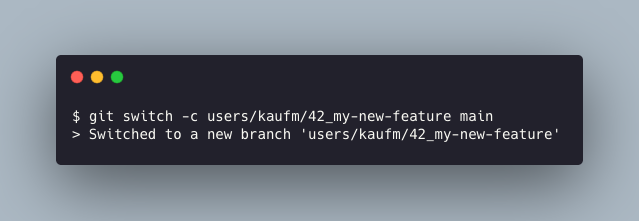
Create your first modifications and commit and push them to the server. It does not matter what you modify – you could just add a blank line to a file. You can overwrite the change later anyway. Add, commit, and push the change:
$ git add .
$ git commit
$ git push --set-upstream origin <branch-name>
For example:

Note that I did not specify the -m parameter in git commit to specify the commit message. I prefer that my default editor opens the COMMIT_EDITMSG so that I can edit the commit message there. This way I can see the files with changes and I have a visual help where the lines should break. Make sure you have set your editor correct if you want to do this. If, for example, you prefer visual studio code, you can set it as your default editor with:
$ git config --global core.editor "code --wait"

Now you create a pull request in draft mode. This way the team knows that you are working on that specific topic. A quick view on the list of open pull requests should give you a nice overview on the topics the team is currently working on.
Note that I use the GitHub CLI to interact with pull requests as I find it easier to read and understand than to use screenshots of the web UI. You can do the same using the web UI.
$ gh pr create --fill --draft
The option --fill will automatically set the title and description of the pr from your commit. If you have omitted the -m argument when committing your changes and if you have added a multi-line commit message in your default editor, the first line will be the title of the pull request and the rest of the message the body. You could also set title (--title or -t) and body (--body or -b) directly when creating the pull request instead of using the --fill option.
You can now start working on your topic. And you can use the full power of git. If you want to add changes to your previous commit, for example, you can do so with the --amend option:
$ git commit --amend
Or, if you want to combine the last three commits into one single commit:
$ git reset --soft HEAD~3
$ git commit
If you want to merge all the commits in the branch into one commit you could run the following command:
$ git reset --soft main
$ git commit
If you want complete freedom to rearrange and squash all your commits you can use interactive rebase:
$ git rebase -i main
To push the changes to the server you use the following command:
$ git push origin +<branch>
In our example:
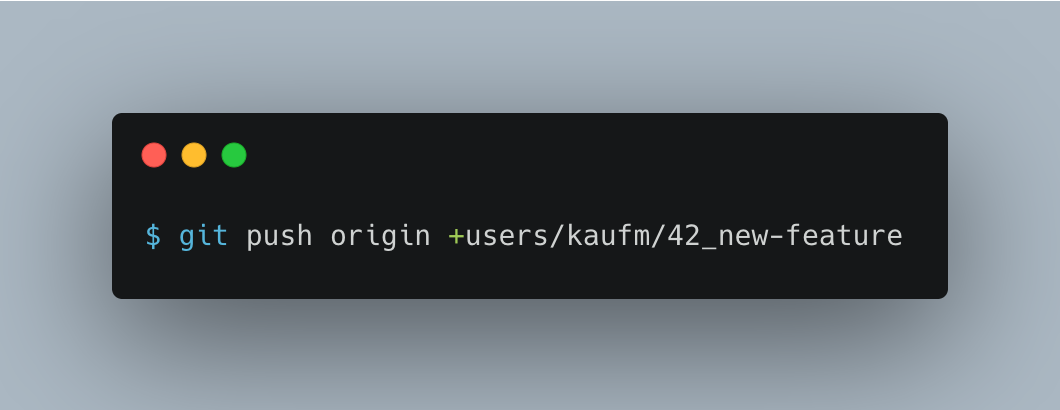
The plus before the branch name causes a force push to the specific branch only. If you are not messing with your branch history, you can perform a normal git push without specifying origin and the branch name. If your branches are well protected and you know what you are doing a normal force push might be more convenient:
$ git push -f
If you want help or opinions of your teammates on your code at that stage, you can mention them in comments in the pull request. If they want to propose changes, they use the suggestions feature in pull request comments. This way you apply the changes, and you can make sure that you have a clean state in your repository before doing so.
Whenever you feel your work is ready, you change the state of your pull request from draft to ready and activate auto-merge:
$ gh pr ready
$ gh pr merge --auto --delete-branch --rebase
I’ve specified --rebase here as the merge method. This is a good merge strategy for small teams that like to craft a good and concise commit history but still want it to be linear. If you prefer --squash or --merge adjust your merge strategy accordingly. Squash is good for bigger teams or teams that are not used to craft very concise commit messages. Merge is only good for small teams with only short-lived branches that want to keep their branches visible in the history.
Your reviewers can still create suggestions in their comments, and you can keep collaborating. But once all approvals and all automated checks have completed, the pull request will be merged automatically, and the branch gets deleted. The automated checks run on the pull_request trigger and can include installing the application in an isolated environment and running all sorts of tests.
If your pull request has been merged and the branch has been deleted, you clean up your local environment:
$ git switch main
$ git pull --prune
This will change your current branch to main, pull the changes from the server, and delete the local branches that has been deleted on the server.
Releasing
Once your changes have been merged to main, the push trigger on main will start the CI build and the deployment to production. Independent whether you use staged environments or a ring-based approach for your releases. If you release your software as a service – like a web application, mobile app, or a cloud service – then your are done here. If your release fails at some point your fix the issue in a new topic branch and roll forward.
But, if you have to maintain multiple versions in the wild and provide hotfixes for them, you can use tags together with semantic versioning and GitHub releases.
About semantic versioning
Semantic versioning is a formal convention for specifying version numbers for software. It consists of different parts in the version number with different meanings. Examples for semantic version numbers are 1.0.0 or 1.5.99-beta. The format is:
<major>.<minor>.<patch>-<pre>
Major version: A numeric identifier that gets increased if the version is not backwards compatible and has breaking changes. An update to a new major version must be handled with caution! A major version of zero is for the initial development.
Minor version: A numeric identifier that gets increased if new features are added and the version is backward compatible to the previous version – meaning it can be updated without breaking anything if you want the new functionality.
Patch: A numeric identifier that gets increased if bugfixes get released that are backwards compatible to previous versions. New patches should always be installed.
Pre version: A text identifier that is appended using a hyphen. The identifier must only use ASCII alphanumeric characters and hyphens ([0-9A-Za-z-]). The longer the text, the smaller the pre-version (meaning -alpha < -beta < -rc). A pre-release version is always smaller than a normal version (1.0.0-alpha < 1.0.0).
See https://semver.org/ for the complete specification.
You can use the Conventional Commits specification to provide information in your commit messages what kind of change the commit contains. This way you can use GitVersion to automatically create semantic versions of your commit using a special configuration.
Create your release
Create a release with the tag containing your semantic version and release notes:
$ gh release create <tag> --notes "<release notes>"
For example:
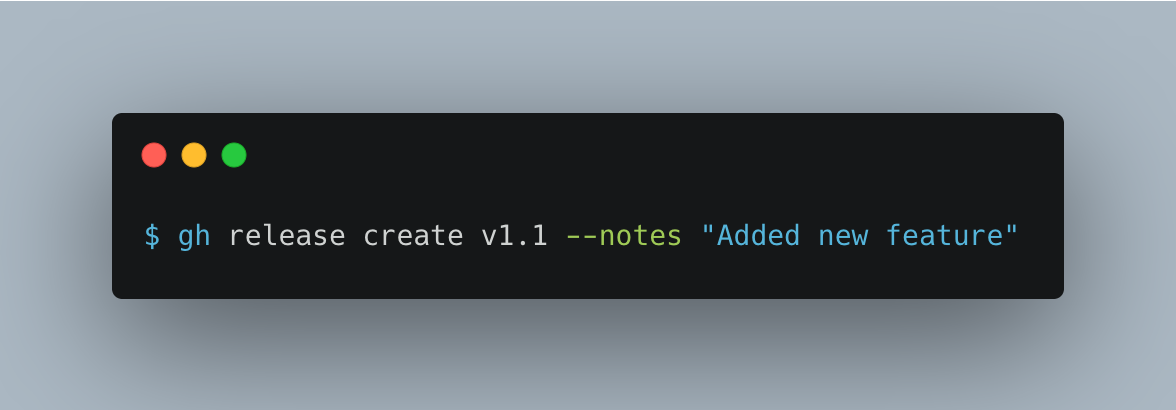
If you use the UI to create the release you can automatically generate release notes from your commit messages. This is not available from the CLI yet.

Use the release trigger in a workflow to release the application:
on:
release:
types: [created]
You can use GitVersion to automatically generate version numbers from your tag and bump them in the build. Note that you have to perform a shallow clone (fetch-depth: 0) for this to work:
- uses: actions/checkout@v2
with:
fetch-depth: 0
- name: Install GitVersion
uses: gittools/actions/gitversion/setup@v0.9.7
with:
versionSpec: '5.x'
- name: Determine Version
id: gitversion
uses: gittools/actions/gitversion/execute@v0.9.7
The calculated final semantic version number is stored as the environment variable $GITVERSION_SEMVER. You could use it like this:
- name: 'Change NPM version'
uses: reedyuk/npm-version@1.1.1
with:
version: $GITVERSION_SEMVER
You can find a complete example of a release workflow here.
Hotfix
If you have to provide a hotfix for an older release, you create a new hotfix branch based on the tag of the release:
$ git switch -c <hotfix-branch> <tag>
$ git push --set-upstream origin <branch>
For example:

Now switch back to main and fix the bug in a normal, private topic branch (for example users/kaufm/666_fix-bug). We fix bugs using the upstream first principle. If you’re finished, cherry-pick the commit with the fix to the hotfix branch:
$ git switch <hotfix-branch>
$ git cherry-pick <commit SHA>
$ git push
You can use the SHA of the commit you want to cherry-pick or use the name of the branch, if the commit is the tip of the branch:

This will cherry-pick the tip of the topic branch. Here you can see the process of performing hotfixes upstream first:

You could also merge the fix to main first and then cherry pick the commit from there. This ensures that the code adheres to all your branch policies.
And you could also cherry-pick into a temporary branch based on the hotfix branch and merge the cherry-picked fix using another pull request. This depends on how complex your environment is and how big the differences between the main branch and the hotfix branch are.
Adjust the workflow to your needs here.
Automation
If you have a workflow with naming conventions, there are certain sequences of commands that you use very often. To reduce typos and simplify your workflow, you can automate these using git aliases. The best way to do this is to edit your .gitconfig in the editor of your choice:
$ git config --global --edit
Add a section [alias] if it does not exist yet and add an alias like this:
[alias]
mfstart = "!f() { \
git switch -c users/$1/$2_$3 && \
git commit && \
git push --set-upstream origin users/$1/$2_$3 && \
gh pr create --fill --draft; \
};f"
This alias is called mfstart and would be called specifying the username, issue id, and topic:
$ git mfstart kaufm 42 new-feature
It switches to a new branch and commits the current changes in the index, pushes them to the server and creates a pull request.
You can reference individual arguments ($1, $2, …) or all arguments using $@. If you want to chain commands independent of the exit code, you must terminate a command using a semicolon ;. If you want the next command to only execute if the previous one was successful, you can use && to chain the commands. Note that you have to end each line with the backslash \. This is also the character you use to escape quotation marks.
You can add if statements to branch your logic:
mfrelease = "!f() { \
if [[ -z \"$1\" ]]; then \
echo Please specify a name for the tag; \
else \
gh release create $1 --notes $2; \
fi; \
};f"
Or you can store values in variables to use them later – like in this example the current name of the branch your HEAD points to:
mfhotfix = "!f() { \
head=$(git symbolic-ref HEAD --short); \
echo Cherry-pick $head onto hotfix/$1 && \
git switch -c hotfix/$1 && \
git push --set-upstream origin hotfix/$1 && \
git cherry-pick $head && \
git push; \
};f"
These are just examples, and the automation depends a lot on the details of the way you work. But it is a very powerful tool and can help you to get more productive.
Conclusion
The perfect git workflow for your team depends on many things:
- The number of developers working on one product
- The complexity of the product
- If you use a mono repo approach or if you use multiple repos per product
- The experience with git your developers have
- Your git service (GitHub, GitLab, Bitbucket,…)
- How you release your product
- And so on
There is no one-size-fits-all solution. But teams need some kind of guidance, either if they are new to git or change the platform. Or, if they have an old workflow that needs to be adopted to a new release process or git system.
I hope MyFlow is a good starting point for many teams. But don’t forget to adopt the workflow to your needs!
I posted MyFlow also on GitHub to make it easier to discuss topics or to contribute.

Thank you for putting a word on the setup we have been using for the last year or so. It allows us to keep our master branch clean, we deploy directly from master once a day. If it pass all the automatic tests in the test environments, then it goes straight into production.
Something one could only dream about a couple of years ago. 🙂