
Dies ist der vierte Teil der Serie zum Exception Handling:
In diesem Teil der Serie wollen wir das Error Handling einer Anwendung aus architektonischer Sicht betrachten. Der wichtigste Aspekt dabei ist sicherlich das Thema Sicherheit.
Sicherheit
Wenn ein Fehler im Betrieb auftritt, dann ist es nötig so viele Informationen wie möglich über diesen Fehler zu haben. Dies betrifft besonders den StackTrace. Dieser sollte bei der Fehlerbehandlung ja immer erhalten bleiben. Jetzt sind der StackTrace und andere ausführliche Informationen zu Fehlern natürlich auch eine Menge Informationen, die von Angreifern benutzt werden können.
Ein schönes Beispiel dafür ist das Köster Framework. Dieses war (oder ist) anfällig für SQL-Injection. Und es hat sehr ausführliche Fehlermeldungen – die neben dem StackTrace auch noch das gesamte SQL-Query ausgegeben haben, dass ausgeführt wurde. Jetzt gab es bei Köster einen WebPart für Dateneingabe. Hat man hier mit Hochkommata getrennte SQL-Anweisungen eingetragen, dann konnte man diese Statements perfekt mithilfe der Fehlermeldungen debuggen. So etwas darf natürlich nie vorkommen!
Deshalb ist es wichtig an der richtigen Stelle die Exceptions zu ersetzen. Der ausführliche Fehler sollte aber in ein Log für die spätere Analyse geschrieben werden. Er kann dann durch einen neuen ersetzt werden: entweder einen neutralen (wie mit der Correlation ID in SharePoint) oder durch einen Benutzerfreundlichen.
Datenkonsistenz
Neben der Sicherheit ist natürlich auch darauf zu achten die Datenkonsistenz zu gewährleisten. Hierbei ist es wichtig zu unterscheiden, ob ein Fehler kritisch ist oder nicht. Bei kritischen Fehlern ist es besser alle Daten nochmals neu zu laden. Bei einfachen Fehlern reicht es vielleicht die Aktion einfach zu wiederholen.
Operations
Während der Entwicklung denkt oft niemand daran, dass am Ende eine Anwendung auch betrieben werden muss. Da werden oft fleißig “ThreadAbortException” ins Log geschrieben, wenn eine Redirect durchgeführt wird. Niemand denkt daran, dass dieser Fehler einmal von einem Administrator nachverfolgt wird. Oder es werden fleißig Fehler gelogged ohne den Benutzer zu informieren. Irgendein Admin wird ja schon das Log ständig überwachen.
Für operations ist es extem wichtig, dass alle Fehler, aus denen sich eventuell nötige Maßnahmen ergeben, sauber mit den richtigen Kategorien und der richtigen Severity ins Log geschrieben werden. Am besten das Eventlog, damit die Anwendung sich in Tools wie SCCM integrieren lässt.
Beispiel
Wie können nun diese Aspekte in der Praxis umgesetzt werden? Am besten wir betrachten das anhand eines Beispiels. Eine Architektur für eine Anwendung könnte z.B. so aussehen:
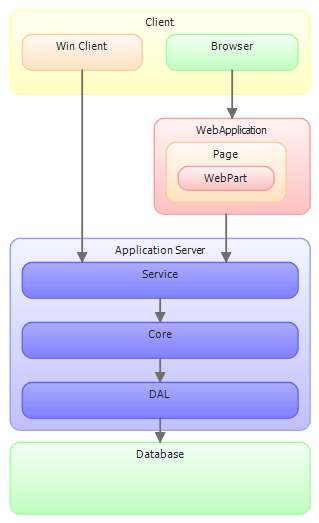
Data Access Layer (DAL)
In der Datenzugriffsschicht ist die Datenkonsistenz der wichtigste Belang. Sie können wir gewährleisten, wenn die die “strong guarantee” mit Transaktionen durchsetzen. Ansonsten können die Fehler einfach durchgereicht werden. Auf keinen Fall sollten hier Fehler geschluckt oder durch eigene ersetzt werden. Die Gründe für Fehler hier können vielfältig sein: Datenbank nicht erreichbar, Deadlocks, Konfigurationsfehler etc. Wie können bestimmt nicht alle antizipieren. Außerdem wissen wir an der Stelle zu wenig über den Kontext um sinnvolle Informationen zu ergänzen. Deshalb einfach Transaktion mit einem “Roll-Back” verwerfen und Exception mit throw weiterleiten.
Business Layer / Domain Layer / Core
Hier steckt das ganze wissen über den Kontext. Deshalb sollte hier Exception-Translation verwendet werden um dem User sinnvolle Fehlermeldungen zurückzugeben. Wichtig ist dabei den ursprünglichen Fehler nicht zu verlieren. An dieser Stelle der Anwendung sollte auch eine Klassifizierung der Fehler vorgenommen werden. Ist der Fehler kritisch? Ist es sicher die Aktion zu wiederholen? Sollen lieber alle Datenerneut geladen werden? Diese Informationen geben wir am besten durch eigene Exception-Typen bekannt.
Service
Der Service bietet zum ersten Mal eine Fläche für Angreifer. Hier sollte also keine unserer mühsam aufbereiteten Ausnahmen zurückgegeben werden. Damit wir den Fehler aber später wiederfinden sollte er mit eine Correlation ID in das Anwendungslog geschrieben werden. Dann kann eine neue Ausnahme mit dem “Message”-String der letzten Ausnahme und der Correlation Id erzeugt und geworfen werden. Wichtig ist dabei, die Informationen über die Klassifizierung nicht zu verlieren! Ansonsten kann der Client nicht entsprechend reagieren.
Windows Client
Der Windows Client muss unterscheiden, ob es sich um einen Fehler vom Service oder einen Fehler des Clients handelt. Fehler des Clients dürfen ruhig ausführlich Protokolliert werden. Vielleicht kann der User ja selber etwas dagegen tun (z.B. Konfiguration anpassen). Fehler des Services können mit einem Verweis an die Hotline unter Verwendung der Correlation Id behandelt werden:
public void SaveSalesOrder(SalesOrderHeader salesOrder)
{
try
{
SalesOrderService service = new SalesOrderService();
SalesOrderForm form = new SalesOrderForm(service);
form.Show();
}
catch (ServiceException ex)
{
// There was an error on the server
// Provide basic information and refer to helpdesk with correlation id.
string msg = string.Format(
@"There was an error updating the sales order: {0}
Please try again later or contact the hotline for assitance.
The correlation id for the error is: '{1}'",
ex.Message,
ex.CorrelationId);
MessageBox.Show(msg);
}
catch (Exception ex)
{
// There was an error inside the client. Log to the eventlog and display it to the user.
WriteTrace(TraceEventType.Critical, ex);
MessageBox.Show("There was an unexpected error in the application. " + ex.Message);
}
}
Außerdem muss natürlich auf die Klassifizierung reagiert und ggf. die Anwendung neu gestartet werden. Dies könnte so erfolgen:
public void FooBar()
{
try
{
Foo();
Bar();
}
catch (CustomException)
{
FixProblem();
}
catch (Custom2Exception ex)
{
ReportErrorAndContinue(ex);
}
catch (Custom3Exception ex)
{
ReportErrorAndShutDown(ex);
}
catch (Exception ex)
{
ReportGenericError(ex);
throw;
}
finally
{
CleanUpResources();
}
}
WebApplication
Für die WebApplication gilt eigentlich das gleiche wie für den Service. Da hier eine Angriffsfläche besteht sollten nur wenige Informationen nach außen gehen – egal ob vom Service oder aus der WebApplication. Hierzu kann die ASP Infrastruktur verwendet werden: Fehler loggen und auf eine allgemeine Fehlerseite umleiten.
WebParts / UserControls
WebParts sollten ja im Falle eines Fehlers nicht immer gleich zum Ausfall der ganzen Seite führen. Deshalb macht es Sinn hier im Fehlerfalle die Message auf der Seite zu Rendern. Der Ausführliche Fehler sollte aber nur gelogged und nicht ausgegeben werden!
Exception Handling Application Block
Damit man das Rad nicht immer neu erfinden muss hat die Enterprise Library einen Exception Handling Application Block. Mithilfe dieses Blocks kann konfigurativ eingestellt werden welche Ausnahmen wie behandelt werden: Wrap, Replace, Log. Eine ausführliche Beschreibung sprengt aber den Rahmen dieses Posts.
